
15 sept 2010
22 ago 2010
Árbol AVL
Árbol AVL es un término usado en computación para referirse a un tipo especial de árbol binario ideado por los matemáticos rusos Adelson-Velskii y Landis. Fue el primer árbol de búsqueda binario auto-balanceable que se ideó.
Contenidos
1 Descripción
1.1 Definición formal
1.1.1 Definición de la altura de un árbol
1.1.2 Definición de árbol AVL
2 Factor de equilibrio
3 Operaciones
3.1 Inserción
3.2 Extracción
3.3 Búsqueda
4 Véase también
5 Enlaces externos
1 Descripción
1.1 Definición formal
1.1.1 Definición de la altura de un árbol
1.1.2 Definición de árbol AVL
2 Factor de equilibrio
3 Operaciones
3.1 Inserción
3.2 Extracción
3.3 Búsqueda
4 Véase también
5 Enlaces externos
Algoritmo de búsqueda A*
Contenido
- 1 Motivación y Descripción
- 2 Propiedades
- 3 Complejidad computacional
- 4 Complejidad en memoria
- 5 Implementación en pseudocódigo
- 5.1 ALGORITMO A*
- 5.2 TRATAR_SUCESOR
- 6 Enlaces externos
17 ago 2010
Haciendo Negocio con Software Libre
Contenido
- ¿Qué es Software Libre?
- Destruyendo mitos.
- Vender servicios, no licencias.
- Iniciando un proyecto.
- Empaquetar.
- Promocionando el producto.
- Soporte comercial.
- Pagando las cuentas.
- La prueba.
- Convicción y conveniencia.
16 ago 2010
Montar Imagenes de CD y DVD en Linux
Linux tiene la posibilidad de montar las imágenes de cd/dvd sin tener que grabarlas. Asumiremos que usas una distribución que usa “apt” para instalar y actualizar paquetes, este es el caso de debian, ubuntu, suse,etc. Asumiremos también que sabes como crear directorios y que sabes qué es “montar” un sistema de ficheros. Vamos al grano.
Con unos cuantos comandos de consola podremos montar distintos tipos de imágenes de CD/DVD fácilmente:
15 ago 2010
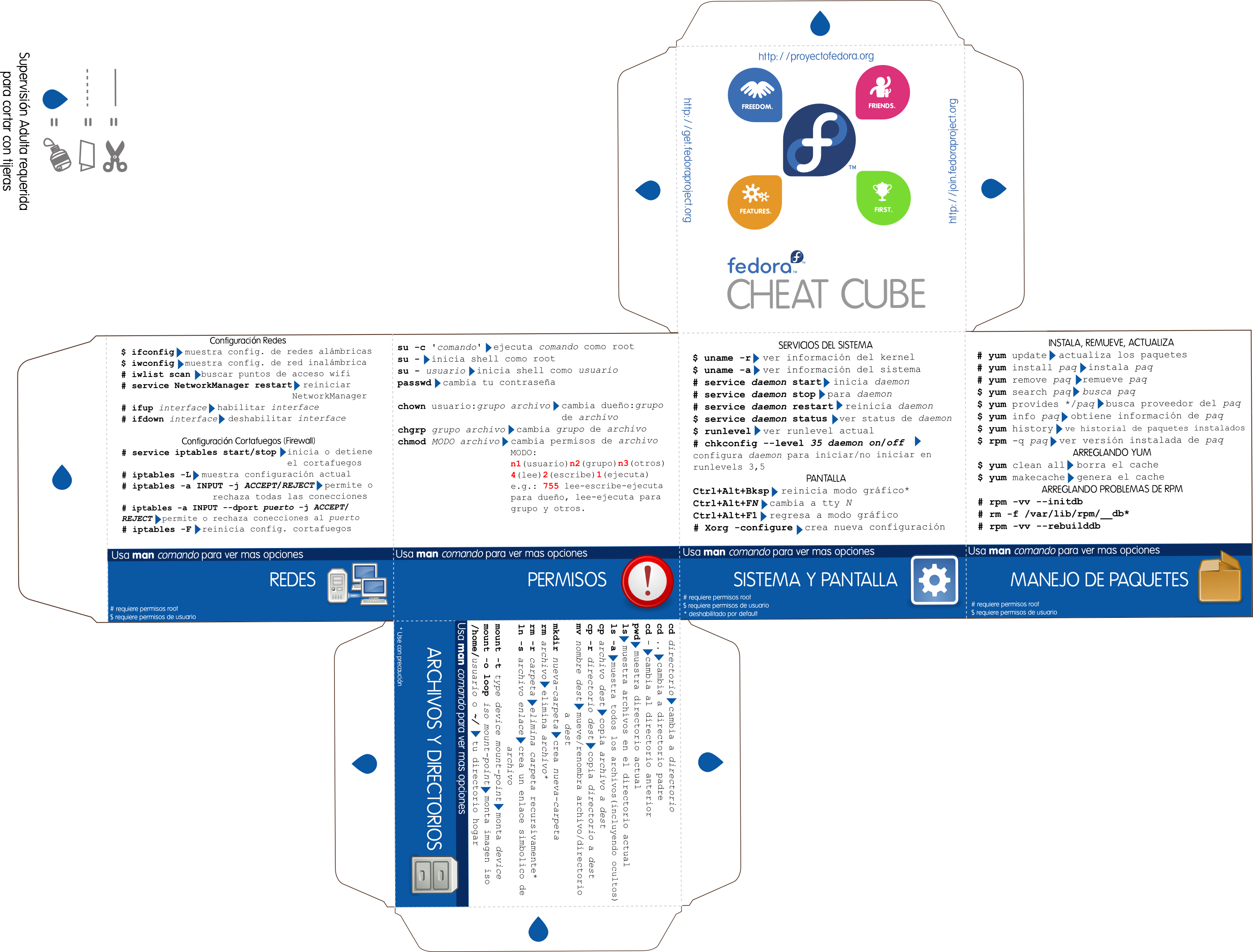
Comandos para administrar un servidor Linux
En este artículo veremos una selección de comandos linux, cada uno con algún ejemplo. Estos comandos son útiles para moverse por el sistema operativo y poder realizar tareas de forma rápida y eficaz.
* Con esta lista no se pretende mostrar (ni mucho menos) todos los comandos linux, sinó un recopilatorio de algunos de ellos y las formas más útiles o comunes de usarlos.
Para obtener ayuda detallada de estos y otros comandos ver el comando man de más abajo. Los comandos están ordenados alfabéticamente:
* Con esta lista no se pretende mostrar (ni mucho menos) todos los comandos linux, sinó un recopilatorio de algunos de ellos y las formas más útiles o comunes de usarlos.
Para obtener ayuda detallada de estos y otros comandos ver el comando man de más abajo. Los comandos están ordenados alfabéticamente:
1 ago 2010
FAILOVER
No permita que el proceso de failover interrumpa otra vez su operación. Hay opciones; es cuestión de elegir la que más conviene en cada caso.
Las empresas, sin importar su tamaño, piden entrega de aplicaciones 7X24 y las fallas de los servidores, el tiempo muerto por mantenimiento y los desastres naturales no son excusas válidas.
Quien tenga como trabajo el mantener las aplicaciones clave siempre operativas debería considerarse afortunado porque hoy existen más opciones para mantener vivas las aplicaciones que nunca antes.
Con las herramientas disponibles en la actualidad, las organizaciones tienen menos pretextos -ya ni siquiera los presupuestales- para evitar que se caigan los sistemas debido a un failover mal realizado y sin recurrir a tardados procesos de restauración manual de las aplicaciones de misión crítica desde un respaldo.
23 jul 2010
16 jul 2010
ISO 27000
Contenido
Origen
La serie 27000
Contenido
Beneficios
¿Cómo adaptarse?
Aspectos Clave
Enlace del Documento >>
Origen
La serie 27000
Contenido
Beneficios
¿Cómo adaptarse?
Aspectos Clave
Enlace del Documento >>
Seguridad y Cobit
Contenido
* Introducción y antecedentes
* Modelos de gestión
* Auditoría y Control Interno
* La Seguridad y la Empresa
Enlace del Documento >>
* Introducción y antecedentes
* Modelos de gestión
* Auditoría y Control Interno
* La Seguridad y la Empresa
Enlace del Documento >>
15 jul 2010
ITIL - MANUAL DE HÉROES
Lo que usted puede esperar en este manual de referencia >
El objetivo de este trabajo es ayudar a entender el verdadero espíritu de ITIL sin perderse en tecnojergas de moda. Para mantenerle con los pies en el suelo, voy a comenzar por lo básico de ITIL, pero centrándome más en la implementación de ITIL. No se preocupe si acaba de empezar con ITIL, este documento está escrito de manera suficientemente sencilla para cualquier persona con nociones básicas de TI.
12 jul 2010
Manual SQL
Indice
1. Introducción
2. Consultas de Selección
3. Criterios de Selección
4. Agrupamiento de Registros
5. Consultas de Acción
. Tipos de Datos
7. SubConsultas
8. Consultas de Referencias Cruzadas
9. Consultas de Unión Internas
10. Consultas de Unión Externas
11. Estructuras de las Tablas
12. Consultas con Parámetros
13. Bases de Datos Externas
14. Omitir los Permisos de Ejecución
15. La Cláusula PROCEDURE
16. Anexos
Enlace del Documento >>
1. Introducción
2. Consultas de Selección
3. Criterios de Selección
4. Agrupamiento de Registros
5. Consultas de Acción
. Tipos de Datos
7. SubConsultas
8. Consultas de Referencias Cruzadas
9. Consultas de Unión Internas
10. Consultas de Unión Externas
11. Estructuras de las Tablas
12. Consultas con Parámetros
13. Bases de Datos Externas
14. Omitir los Permisos de Ejecución
15. La Cláusula PROCEDURE
16. Anexos
Enlace del Documento >>
9 jul 2010
TSQL2
TSQL2 es un conjunto de extensiones temporales propuestas para SQL con el objetivo de poder tratar bases de datos temporales. Propone diversos tipos especiales de tablas:
* Tablas de instantánea.
* Tablas de estado de tiempo válido.
* Tablas de evento de tiempo válido.
* Tablas de tiempo de transacción.
* Tablas de estado bitemporales.
* Tablas de evento bitemporales.
* Tablas de instantánea.
* Tablas de estado de tiempo válido.
* Tablas de evento de tiempo válido.
* Tablas de tiempo de transacción.
* Tablas de estado bitemporales.
* Tablas de evento bitemporales.
Base de datos temporal
Una Base de datos temporal es un sistema de gestión de base de datos (DBMS) el cual implementa y trata con especial énfasis aspectos temporales, teniendo un modelo de datos temporal y una versión temporal del lenguaje de consulta estructurado, (SQL). Entre las diversas propuestas de implementación, la más extendida es TSQL2.
Especificando más profundamente, los aspectos temporales normalmente incluyen tiempo de validez y tiempo de transacción. La combinación de estos dos atributos forman un dato bitemporal.
* Tiempo de validez indica el periodo de tiempo en el cual un hecho es verdad en el mundo real.
* Tiempo de transacción indica el periodo de tiempo en el cual un hecho está guardado en la base de datos.
* Dato Bitemporal es la combinación del tiempo de validez y el tiempo transaccional.
Estos dos periodos de tiempo no tienen que ser idénticos para un mismo hecho. Imagine una base de datos temporal guardando datos sobre el siglo veinte. El tiempo de validez sobre esos hechos estará comprendido entre el año 1901 y el año 2000, sin embargo el tiempo transaccional empezará cuando insertemos esos hechos en la base de datos, por ejemplo, 25 de diciembre del 2006.
Base de datos espacial
Base de datos espacial (spatial database) es un sistema administrador de bases de datos que maneja datos existentes en un espacio o datos espaciales. El espacio establece un marco de referencia para definir la localización y relación entre objetos. El que normalmente se utiliza es el espacio físico que es un dominio manipulable, perceptible y que sirve de referencia. La construcción de una base de datos geográfica implica un proceso de abstracción para pasar de la complejidad del mundo real a una representación simplificada que pueda ser procesada por el lenguaje de las computadoras actuales. Este proceso de abstracción tiene diversos niveles y normalmente comienza con la concepción de la estructura de la base de datos, generalmente en capas; en esta fase, y dependiendo de la utilidad que se vaya a dar a la información a compilar, se seleccionan las capas temáticas a incluir.
La estructuración de la información espacial procedente del mundo real en capas conlleva cierto nivel de dificultad. En primer lugar, la necesidad de abstracción que requieren los computadores implica trabajar con primitivas básicas de dibujo, de tal forma que toda la complejidad de la realidad ha de ser reducida a puntos, líneas o polígonos. En segundo lugar, existen relaciones espaciales entre los objetos geográficos que el sistema no puede obviar; la topología, que en realidad es el método matemático-lógico usado para definir las relaciones espaciales entre los objetos geográficos puede llegar a ser muy compleja, ya que son muchos los elementos que interactúan sobre cada aspecto de la realidad.

Contenidos
* 1 Datos espaciales
o 1.1 Puntos
o 1.2 Líneas
o 1.3 Polígonos
* 2 Álgebra
o 2.1 Operadores de selección
+ 2.1.1 Point Query (PQ)
+ 2.1.2 Range or region query (WQ)
+ 2.1.3 Agregación espacial
+ 2.1.4 Join espacial
* 3 Métodos de acceso espacial
* 4 Lenguajes de consulta espacial
* 5 Aplicaciones
o 5.1 SIG Puros
o 5.2 Ad-hoc
o 5.3 Bases de datos con extensiones para bases de datos espaciales
* 6 Enlaces externos
* 1 Datos espaciales
o 1.1 Puntos
o 1.2 Líneas
o 1.3 Polígonos
* 2 Álgebra
o 2.1 Operadores de selección
+ 2.1.1 Point Query (PQ)
+ 2.1.2 Range or region query (WQ)
+ 2.1.3 Agregación espacial
+ 2.1.4 Join espacial
* 3 Métodos de acceso espacial
* 4 Lenguajes de consulta espacial
* 5 Aplicaciones
o 5.1 SIG Puros
o 5.2 Ad-hoc
o 5.3 Bases de datos con extensiones para bases de datos espaciales
* 6 Enlaces externos
OLTP
OLTP es la sigla en inglés de Procesamiento de Transacciones En Línea (OnLine Transaction Processing) es un tipo de sistemas que facilitan y administran aplicaciones transaccionales, usualmente para entrada de datos y recuperación y procesamiento de transacciones (gestor transaccional). Los paquetes de software para OLTP se basan en la arquitectura cliente-servidor ya que suelen ser utilizados por empresas con una red informática distribuida.
El término puede parecer ambiguo, ya que puede entenderse "transacción" en el contexto de las "transacciones computacionales" o de las "transacciones en bases de datos". También podría entenderse en términos de transacciones de negocios o comerciales. OLTP también se ha utilizado para referirse a la transformación en la que el sistema responde de inmediato a las peticiones del usuario. Un cajero automático de un banco es un ejemplo de una aplicación de procesamiento de transacciones comerciales.
La tecnología OLTP se utiliza en innumerables aplicaciones, como en banca electrónica, procesamiento de pedidos, comercio electrónico, supermercados o industria.
Contenido
* 1 Requerimientos
* 2 Beneficios
* 3 Inconvenientes
Almacén operacional de los datos
También llamado ODS (del inglés Operational Data Store) es un contenedor de datos activos, es decir operacionales que ayudan al soporte de decisiones y a la operación. Está entre un OLAP y un OLTP. Su función es integrar los datos al igual que en el Data warehouse pero con una ventana de actualización muy pequeña (del orden de minutos) y con mucho menos detalle.
8 jul 2010
Almacén de datos
En el contexto de la informática, un almacén de datos (del inglés data warehouse) es una colección de datos orientada a un determinado ámbito (empresa, organización, etc.), integrado, no volátil y variable en el tiempo, que ayuda a la toma de decisiones en la entidad en la que se utiliza. Se trata, sobre todo, de un expediente completo de una organización, más allá de la información transaccional y operacional, almacenado en una base de datos diseñada para favorecer el análisis y la divulgación eficiente de datos (especialmente OLAP, procesamiento analítico en línea). El almacenamiento de los datos no debe usarse con datos de uso actual. Los almacenes de datos contienen a menudo grandes cantidades de información que se subdividen a veces en unidades lógicas más pequeñas dependiendo del subsistema de la entidad del que procedan o para el que sean necesario.
DBA
El administrador de base de datos (DBA) es la persona responsable de los aspectos ambientales de una base de datos. En general esto incluye:
- Recuperabilidad - Crear y probar Respaldos
- Integridad - Verificar o ayudar a la verificación en la integridad de datos
- Seguridad - Definir y/o implementar controles de acceso a los datos
- Disponibilidad - Asegurarse del mayor tiempo de encendido
- Desempeño - Asegurarse del máximo desempeño incluso con las limitaciones
- Desarrollo y soporte a pruebas - Ayudar a los programadores e ingenieros a utilizar eficientemente la base de datos.
El diseño lógico y físico de las bases de datos a pesar de no ser obligaciones de un administrador de bases de datos, es a veces parte del trabajo. Esas funciones por lo general están asignadas a los analistas de bases de datos ó a los diseñadores de bases de datos.
Contenido
- 1 Deberes
- 2 Definición de base de datos
- 3 Disponibilidad
- 4 Recuperabilidad
- 5 Integridad
- 6 Seguridad
- 7 Rendimiento
- 8 Desarrollo/Soporte a pruebas
ACID
En bases de datos se denomina ACID a la propiedad de una base de datos para realizar transacciones seguras. Así pues ACID compliant define a un sistema de gestión de bases de datos que puede realizar transacciones seguras.
En concreto ACID es un acrónimo de Atomicity, Consistency, Isolation and Durability: Atomicidad, Consistencia, Aislamiento y Durabilidad en español.
7 jul 2010
Modelo Relacional | SI
El modelo relacional
* Conceptos del modelo relacional
* Convertir E-R a modelo relacional
* Conceptos del modelo relacional
* Convertir E-R a modelo relacional
Sistema de gestión de base de datos
El propósito general de los sistemas de gestión de base de datos es el de manejar de manera clara, sencilla y ordenada un conjunto de datos que posteriormente se convertirán en información relevante, para un buen manejo de datos.
Contenido
1 Propósito
2 Objetivos
3 Ventajas
4 Inconvenientes
5 Arquitectura de un SGBD
6 Productos SGBD disponibles en el mercado
6.1 SGBD libres
6.2 SGBD gratuitos
6.3 ejemplos SGBD comerciales
7 Véase también
1 Propósito
2 Objetivos
3 Ventajas
4 Inconvenientes
5 Arquitectura de un SGBD
6 Productos SGBD disponibles en el mercado
6.1 SGBD libres
6.2 SGBD gratuitos
6.3 ejemplos SGBD comerciales
7 Véase también
Reglas de integridad
Una vez definida la estructura de datos del modelo relacional, pasamos a estudiar las reglas de integridad que los datos almacenados en dicha estructura deben cumplir para garantizar que son correctos.
Al definir cada atributo sobre un dominio se impone una restricción sobre el conjunto de valores permitidos para cada atributo. A este tipo de restricciones se les denomina restricciones de dominios. Hay además dos reglas de integridad muy importantes que son restricciones que se deben cumplir en todas las bases de datos relacionales y en todos sus estados o instancias (las reglas se deben cumplir todo el tiempo). Estas reglas son la regla de integridad de entidades y la regla de integridad referencial. Antes de definirlas, es preciso conocer el concepto de nulo.
6 jul 2010
SQL * Plus
¿Qué es SQL*Plus?
SQL*Plus es una poderosa herramienta de Oracle que permite la interacción completa del usuario de la base de datos, para que este efectúe todas las operaciones cotidianas sobre ella, como son:
SQL*Plus es una poderosa herramienta de Oracle que permite la interacción completa del usuario de la base de datos, para que este efectúe todas las operaciones cotidianas sobre ella, como son:
• Consultas a la base de datos.
• Operaciones de actualización sobre los datos.
• Definición de las estructuras para almacenamiento de los datos.
Modelo relacional
El modelo relacional para la gestión de una base de datos es un modelo de datos basado en la lógica de predicado y en la teoría de conjuntos.
Éste es el modelo más utilizado en la actualidad para modelar problemas reales y administrar datos dinámicamente. Tras ser postuladas su bases en 1970 por Edgar Frank Codd, de los laboratorios IBM en San José (California), no tardó en consolidarse como un nuevo paradigma en los modelos de base de datos.
Su idea fundamental es el uso de «relaciones». Estas relaciones podrían considerarse en forma lógica como conjuntos de datos llamados «tuplas». Pese a que esta es la teoría de las bases de datos relacionales creadas por Edgar Frank Codd, la mayoría de las veces se conceptualiza de una manera más fácil de imaginar. Esto es, pensando en cada relación como si fuese una tabla que esta compuestas por registros (las filas de una tabla), que representarían las tuplas, y campos (las columnas de una tabla).
Tabla de contenidos
|
5 jul 2010
Copia de Seguridad
Hacer una copia de seguridad o copia de respaldo (backup en inglés, el uso de este anglicismo está ampliamente extendido) se refiere a la copia de datos de tal forma que estas copias adicionales puedan restaurar un sistema después de una pérdida de información.
La copia de seguridad es útil por varias razones:
Enlace del Documento >>
Base de datos relacional
Una base de datos relacional es una base de datos que cumple con el modelo relacional, el cual es el modelo más utilizado en la actualidad para implementar bases de datos ya planificadas. Permiten establecer interconexiones (relaciones) entre los datos (que están guardados en tablas), y a través de dichas conexiones relacionar los datos de ambas tablas, de ahí proviene su nombre: "Modelo Relacional". Tras ser postuladas sus bases en 1970 por Edgar Frank Codd, de los laboratorios IBM en San José (California), no tardó en consolidarse como un nuevo paradigma en los modelos de base de datos.



Lista de programas, equivalente (Windows-Linux)
- Programas
K-3D ( http://www.k-3d.org/ )
Wings 3D ( http://www.wings3d.com/ )
Art of Illusion ( http://www.artofillusion.org/ )
Blender ( http://www.blender.org/ )
POV-Ray ( http://www.povray.org )
ACDSee
KuickShow ( http://kuickshow.sourceforge.net/ )
ShowImg ( http://www.jalix.org/projects/showimg/ )
Gwenview ( http://gwenview.sourceforge.net/ )
GQview ( http://gqview.sourceforge.net/ )
Eye of GNOME ( http://www.gnome.org/projects/eog/ )
gThumb ( http://gthumb.sourceforge.net/ )
pornview ( http://sourceforge.net/projects/pornview/ )
MyACDSee ( http://myacdsee.sourceforge.net/home/index.php/ )
f-spot ( http://f-spot.org/ )
4 jul 2010

10 Comandos Necesarios
1. Top
Me imaginé que era apropiado poner el "top" en el "top". Aunque "top" es realmente responsable por la publicación de las tareas actualmente en ejecución, también es el primer comando al que los usuarios de Linux recurrimos cuando necesitamos saber que tanto se está usando la memoria (o incluso la cantidad de memoria que tiene el sistema). A menudo dejo la herramienta "top" funcionando en mi escritorio para poder hacer un seguimiento de lo que está pasando en todo momento. A veces, incluso abro una Terminal (por lo general aterm), coloco la ventana donde quiero, y luego oculto el borde de la ventana. Sin un borde, la Terminal no se puede mover, así que siempre tienen un acceso rápido a la información que necesitan.
Top es un sistema de informes en tiempo-real, así que, cuando haya cambios en los procesos, inmediatamente se reflejarán en la ventana de la Terminal. Top tiene algunos argumentos útiles (por ejemplo, el argumento -p, que solo hará un seguimiento "top" de los PIDs de usuarios específicos), pero ejecutándose por defecto, Top te dará toda la información que necesitas sobre las tareas en ejecución.
Me imaginé que era apropiado poner el "top" en el "top". Aunque "top" es realmente responsable por la publicación de las tareas actualmente en ejecución, también es el primer comando al que los usuarios de Linux recurrimos cuando necesitamos saber que tanto se está usando la memoria (o incluso la cantidad de memoria que tiene el sistema). A menudo dejo la herramienta "top" funcionando en mi escritorio para poder hacer un seguimiento de lo que está pasando en todo momento. A veces, incluso abro una Terminal (por lo general aterm), coloco la ventana donde quiero, y luego oculto el borde de la ventana. Sin un borde, la Terminal no se puede mover, así que siempre tienen un acceso rápido a la información que necesitan.
Top es un sistema de informes en tiempo-real, así que, cuando haya cambios en los procesos, inmediatamente se reflejarán en la ventana de la Terminal. Top tiene algunos argumentos útiles (por ejemplo, el argumento -p, que solo hará un seguimiento "top" de los PIDs de usuarios específicos), pero ejecutándose por defecto, Top te dará toda la información que necesitas sobre las tareas en ejecución.
Tutorial Blogger
Hoy en día la tecnología es parte de nuestra vida diaria y sobre todo aquella que se deriva del internet. Escuchamos hablar de páginas web, buscadores, e-mails más potentes, portales y muchas otras cosas que ayudan a la comunicación entre personas, a la educación y al conocimiento.
Pero si hablamos de lo más novedoso de la red, tendremos que hablar de los BLOGS, sitios para publicar información personal, corporativa de negocios, periodística etc.
Pero los blogs se han convertido más en una herramienta de comunicación donde se acerca a las personas entre sí, haciendo más interactiva la relación con la red.
Grandes personalidades y empresas como Andrés Oppenheimer, Noticieros televisa, Periódico el economista, entre otros más, manejan los blogs como la herramienta número uno por encima del e-mail para comunicarse con su público.
Esperamos que puedan descubrir el sin número de posibilidades que les da el BLOG y sobre todo que tengan una herramienta más para seguir siendo competitivos internacionalmente.
3 jul 2010


1 jul 2010
Base de datos jerárquica
Una Base de datos jerárquica es un tipo de Sistema Gestor de Bases de Datos que, como su nombre indica, almacenan la información en una estructura jerárquica que enlaza los registros en forma de estructura de árbol (similar a un árbol visto al revés), en donde un nodo padre de información puede tener varios nodos hijo.
Esta relación jerárquica no es estrictamente obligatoria, de manera que pueden establecerse relaciones entre nodos hermanos. En este caso la estructura en forma de árbol se convierte en una estructura en forma de grafo dirigido. Esta variante se denomina Bases de datos de red.
Contenidos
|
SIG
SISTEMAS DE INFORMACIÓN GERENCIAL (S.I.G.):
Contenido
- DESARROLLO DE UN SISTEMA DE INFORMACIÓN GERENCIAL:
- COMPONENTES DE UN SISTEMA DE INFORMACIÓN GERENCIAL (S.I.G.):
- SISTEMAS EXPERTOS:
- SISTEMAS DE APOYO A LAS DECISIONES (S.A.D.):
Objetivos de la planificación de proyectos
El objetivo de la plantificación del proyecto de software es el de suministrar una estructura que permita al director hacer estimaciones razonables de recursos, costes y agendas. Estas estimaciones se hacen sin un marco de tiempo limitado, al principio de un proyecto de software y deben ser actualizados regularmente a medida que progresa el proyecto.
30 jun 2010
Tipos de usuario informático
En sentido general, un usuario es un conjunto de permisos y de recursos (o dispositivos) a los cuales se tiene acceso. Es decir, un usuario puede ser tanto una persona como una máquina, un programa, etc.
Usuario final
El usuario final de un producto informático (bien sea hardware o software), es la persona a la que va destinada dicho producto una vez que ha superado las fases de desarrollo correspondientes.
Normalmente, el software se desarrolla pensando en la comodidad del usuario final, y por esto se presta especial interés y esfuerzo en conseguir una interfaz de usuario lo más clara y sencilla posible.
Proceso Unificado
El Proceso Unificado de Desarrollo Software o simplemente Proceso Unificado es un marco de desarrollo de software que se caracteriza por estar dirigido por casos de uso, centrado en la arquitectura y por ser iterativo e incremental. El refinamiento más conocido y documentado del Proceso Unificado es el Proceso Unificado de Rational o simplemente RUP.
El Proceso Unificado no es simplemente un proceso, sino un marco de trabajo extensible que puede ser adaptado a organizaciones o proyectos específicos. De la misma forma, el Proceso Unificado de Rational, también es un marco de trabajo extensible, por lo que muchas veces resulta imposible decir si un refinamiento particular del proceso ha sido derivado del Proceso Unificado o del RUP. Por dicho motivo, los dos nombres suelen utilizarse para referirse a un mismo concepto.
Modelo de prototipos
En Ingeniería de software el desarrollo con prototipación, también llamado modelo de prototipos o modelo de desarrollo evolutivo, se inicia con la definición de los objetivos globales para el software, luego se identifican los requisitos conocidos y las áreas del esquema en donde es necesaria más definición. Entonces se plantea con rapidez una iteración de construcción de prototipos y se presenta el modelado (en forma de un diseño rápido).
El diseño rápido se centra en una representación de aquellos aspectos del software que serán visibles para el cliente o el usuario final (por ejemplo, la configuración de la interfaz con el usuario y el formato de los despliegues de salida). El diseño rápido conduce a la construcción de un prototipo, el cual es evaluado por el cliente o el usuario para una retroalimentación; gracias a ésta se refinan los requisitos del software que se desarrollará. La iteración ocurre cuando el prototipo se ajusta para satisfacer las necesidades del cliente. Esto permite que al mismo tiempo el desarrollador entienda mejor lo que se debe hacer y el cliente vea resultados a corto plazo.
Métrica de punto función
La métrica del punto función, definida por Allan Albrecht, de IBM, en 1979 , es un método para medir el tamaño del software. Pretende medir la funcionalidad entregada al usuario independientemente de la tecnología utilizada para la construcción y explotación del software, y también ser útil en cualquiera de las fases de vida del software, desde el diseño inicial hasta la explotación y mantenimiento.
Existen diferentes metodologías de medición, la más popular de las cuales es la mantenida por el International Function Point Users Group (IFPUG).
Herramienta CASE
Las herramientas CASE (Computer Aided Software Engineering, Ingeniería de Software Asistida por Ordenador) son diversas aplicaciones informáticas destinadas a aumentar la productividad en el desarrollo de software reduciendo el coste de las mismas en términos de tiempo y de dinero. Estas herramientas nos pueden ayudar en todos los aspectos del ciclo de vida de desarrollo del software en tareas como el proceso de realizar un diseño del proyecto, calculo de costes, implementación de parte del código automáticamente con el diseño dado, compilación automática, documentación o detección de errores entre otras.
Framework
En el desarrollo de software, un framework es una estructura de soporte definida en la cual otro proyecto de software puede ser organizado y desarrollado. Típicamente, un framework puede incluir soporte de programas, bibliotecas y un lenguaje interpretado entre otros software para ayudar a desarrollar y unir los diferentes componentes de un proyecto.
Un framework representa una arquitectura de software que modela las relaciones generales de las entidades del dominio. Provee una estructura y una metodología de trabajo la cual extiende o utiliza las aplicaciones del dominio.
Educción de requisitos
La educción de requisitos consiste en hallar e identificar los requisitos que debe satisfacer un determinado sistema de información. Se trata de una actividad propia de la ingeniería del software, anterior al análisis de requisitos.
Motivación y etimología
El verbo educir se define como sacar una cosa de otra y se ha adoptado por la dificultad que supone identificar los requisitos de un sistema de información. Aunque aparentemente dichos requisitos vienen dados por el cliente, la realidad es que la mayoría de ellos deben ser investigados por el ingeniero.
Diseño de sistemas
El Diseño de sistemas es el arte de definir la arquitectura de hardware y software, componentes, módulos y datos de un sistema de cómputo para satisfacer ciertos requerimientos. Es la etapa posterior al análisis de sistemas.
El diseño de sistemas tiene un rol más respetado y crucial en la industria de procesamiento de datos. La importancia del software multiplataforma ha incrementado la ingeniería de software a costa de los diseños de sistemas.
Los métodos de Análisis y diseño orientado a objetos se están volviendo en los métodos más ampliamente utilizados para el diseño de sistemas. El UML se ha vuelto un estandard en el Análisis y diseño orientado a objetos. Es ampliamente utilizado para el modelado de sistemas de software y se ha incrementado su uso para el diseño de sistemas que no son software así como organizaciones.
Diseño asistido por computador
El diseño asistido por computador remoto (o computadora u ordenador), abreviado como DAO (diseño asistido por computador) pero más conocido por sus siglas inglesas CAD (Computer Aided Design remote), es el uso de un amplio rango de herramientas computacionales que asisten a ingenieros, arquitectos y a otros profesionales del diseño en sus respectivas actividades. También se llega a encontrar denotado con una adicional "Dc=0" en las siglas CADD, diseño y bosquejo asistido por computadora (Computer Aided Drafting and Design).
Diagrama de flujo de datos
Un diagrama de flujo de datos (DFD) es un modelo lógico-gráfico para representar el funcionamiento de un sistema en un proyecto software. Sus elementos gráficos son círculos, flechas, y rectángulos cerrados o abiertos. Los cerrados representan entidades externas mientras que los abiertos describen almacenes o archivos. Los círculos significan procesos y las flechas flujos de datos desde, o hacia, un proceso.
COCOMO
El Modelo Constructivo de Costes (o COCOMO, por su acrónimo del inglés Constructive Cost Model) es un modelo de estimación de costes de software que incluye tres submodelos, donde cada uno ofrece un nivel de detalle y aproximación cada vez mayor, a medida que avanza el proceso de desarrollo del software: básico, intermedio y detallado.
Fue desarrollado por Barry W. Boehm a finales de los 70 y comienzos de los 80, exponiéndolo detalladamente en su libro "Software Engineering Economics" (Prentice-Hall, 1981).
Contenido
|
Desarrollador de software
Un desarrollador de software es un programador que se dedica a una o más facetas del proceso de desarrollo de software, un ámbito algo más amplio de la programación. Esta persona puede contribuir a la visión general del proyecto más a nivel de aplicación que a nivel de componentes o en las tareas de programación individuales. Los desarrolladores de software suelen estar aún guiados por programadores líderes, pero también abundan los programadores independientes.
29 jun 2010
28 jun 2010
Añadir Archivos
Blogger - Añadir archivos DOC, PDF, PPT, PPS, XLS y otros al blog
es preciso alojarlos en un servicio de alojamiento (hosting) externo a Blogger.
Se explican aquí dos tipos de alternativas, complementarias.
A. Publicar archivos mediante Google Docs.
Primero, hay que registrase en el producto Google Docs (ver http://www.google.com/google-d-s/hpp/hpp_es.html para una visita guiada y acceder al servicio), con los mismos datos que se utilizan para acceder a Gmail. Una vez registrado, puede comenzarse a subirse archivos en los siguientes formatos y con los siguientes límites de tamaño:
- Documentos (máximo 500 MB): HTML, TXT, DOC, RTF, ODT, SXW
- Presentaciones (hasta 10 MB desde el equipo, 2 MB desde Internet y 500 KB por correo electrónico): PPT, PPS -ver nota 1 de este tutorial-
- Hojas de cálculo (máximo 1 MB): CVS, XLS, ODS
27 jun 2010
Agregar Código Fuente en tu Blogger
Para ingresar código fuente en tu blogger te recomiendo SimpleCode. Por ejemplo escribes el código que deseas agregar dentro de tu entrada en blogger y luego le das un click en el boton Process para generar el código.Cuadro de texto
Una de las cosas muy sencillas que podemos insertar en nuestro blog que nos puede ser de utilidad para poner código fuente o lo que queramos para nuestro blog.
La manera de hacerlo en un post será la siguiente:
- En primer lugar nos vamos a nuestro mensaje que queremos escribir, y escribimos lo que queramos en el mensaje y dejamos un espacio con un texto para ponerlo.
- Cambiarmos la vista redarctar a “Edición de HTML” en la pestaña superior de donde escribimos la entrada.
- Copiamos el siguiente código HTML en el lugar donde queremos que esté:
<textarea cols="20" rows="3">Escribo algo de prueba y observaremos el resultado</textarea>
Planes Estratégicos con SI
PLANES ESTRATÉGICOS CON SISTEMAS DE INFORMACIÓN
Si lo descomponemos, al pre-analisis se le puede diferenciar 3 etapas:
i: La comprensión del proyecto.
¿Como lo aplicamos en el sistema?
1.Por medio de una encuesta que nos permita extraer información relevante a
nuestro estudio.
2.Conociendo los objetivos del sistema.
3.Conociendo los aspectos claves del sistema.
26 jun 2010
Auditoria
Concepto de Auditoría
Examen metódico de una situación relativa a un producto, proceso u organización, en materia de calidad, realizado en cooperación con los interesados para verificar la concordancia de la realidad con lo preestablecido y la adecuación al objetivo buscado
Otro Concepto de Auditoría
Actividad para determinar, por medio de la investigación, la adecuación de los procedimientos establecidos, instrucciones, especificaciones, codificaciones y estándares u otros requisitos, la adhesión a los mismos y la eficiencia de su implantación.
Aumentar memoria swap
Con el gparted livecd http://gparted.sourceforge.net/livecd.php
Le quitas espacio a una particion eliminas la swap que tienes y luego creas la nueva swap con el espacio que te queda.
También se puede instalar el gparted en ubuntu y tratar de hacer los cambios desde ahi deshabilitando la swap y redimencionando, pero prefiero el livecd, ademas de que es muy util en otros casos también.

Le quitas espacio a una particion eliminas la swap que tienes y luego creas la nueva swap con el espacio que te queda.
También se puede instalar el gparted en ubuntu y tratar de hacer los cambios desde ahi deshabilitando la swap y redimencionando, pero prefiero el livecd, ademas de que es muy util en otros casos también.

{kind=link}
{kind=link}

Gerencia de Proyectos
INTRODUCCION
El presente trabajo muestra como debe de aplicarse una plaza de gerente de proyectos para una empresa y como debe un gerente de sistemas sacarle el mejor provecho a dicha plaza.
También muestra como debe de ayudar al gerente de proyectos a realizar su trabajo y cuales deben de ser sus perfiles del puesto al contratarlo. También muestra las actividades que debe de ponerle el gerente de sistemas a su gerente de proyectos y como este las debe de presentar ya sea en informes o cualquier otro tipo de información. Aquí se presentan unos bosquejos de presentación de proyectos para que sean tomados en cuenta a la hora de presentar dichos informes.
Incluye también una parte para el departamento de recursos humanos de cómo debe de ser colocada la plaza de gerente de proyectos en la organización para que este produzca el 100% de sus tareas a realizar.
Outsourcing
INTRODUCCION.
Este trabajo presenta a la subcontratación (outsourcing), como un enfoque que puede ayudar a las compañías a convertirseen exitosas. Las empresas buscan constantemente soluciones para adaptarse a los nuevos retos que enfrentan. Todas las áreas de la administración han cambiado considerablemente en los últimos años para superar estos retos. La competencia que entablan las organizaciones, la globalización, los ciclos de vida menores para los productos y los cambios tecnológicos son algunos de los principales problemas que las afectan y el outsourcing nos ayuda a superarlos.
Se detallan las razones por las cuales puede ser más eficiente adquirir los bienes y servicios requeridos de fuentes externas (subcontratación) que de fuentes internas, los puntos esenciales para lograr una subcontratación exitosa, las principales ventajas y desventajas de este enfoque y por último, ejemplo de una empresa transnacional que labora en guatemala.
Objetivos
El objetivo de este trabajo es mostrar la importancia estratégica del proceso subcontratación (outsourcing) como una forma de disminuir costos, incrementar la eficiencia de las organizaciones y aumentar la visión estratégica.
Sistemas de Información Contemporánea
PARTE IV
LA ADMINISTRACIÓN DE LOS SISTEMAS DE INFORMACIÓN CONTEMPORÁNEA
Resumen Capítulo 18
El control de los sistemas de información
Demostrar por qué los sistemas de información automatizados son tan vulnerables a la destrucción, errores y abusos.
Las instituciones se han hecho tan dependientes de los sistemas de información computarizados que deben tomar medidas especiales para asegurar que estén adecuadamente controlados. Con los datos concentrados en forma electrónica y muchos procedimientos haciéndose invisibles por la automatización, los sistemas son vulnerables a la destrucción, mal uso, error, fraude y fallas en el software o en el hardware. El efecto del desastre en un sistema computarizado puede ser mayor que en los sistemas manuales, porque todos los registros para una función o institución particular pueden perderse o destruirse. Los sistemas en línea y los que utilizan telecomunicaciones son especialmente vulnerables porque los datos y los archivos pueden ser accesados de inmediato y directamente mediante terminales de computadora en muchos puntos en la red de telecomunicaciones. Virus de computadora pueden extenderse alegremente de un sistema a otro, atrofiando la memoria de la computadora o destruyendo programas y datos.
Soporte para la Administración
PARTE IV
Resumen Capítulo 15
Sistemas de trabajo de conocimientos e información
Definir el trabajo de información y la economía de información.
Las economías avanzadas en los Estados Unidos, Canadá y Europa se han transformado de economías industriales, en donde la mayor parte de la riqueza provenía de la fabricación, en economías de información, en donde la mayor parte de la riqueza se origina en la producción de información y conocimientos. En la actualidad, la mayor parte de los trabajadores realizan trabajo de información. Este trabajo consiste principalmente en la creación y procesamiento de la información.
Describir las funciones de los trabajadores del conocimiento y los datos en una institución.
En la actualidad existen dos clases de trabajadores de la información: Los trabaja dores del conocimiento son empleados como los ingenieros, arquitectos, científicos o abogados, cuya labor principal es crear información nueva para la institución. Los trabajadores del conocimiento interpretan la base de los conocimientos externos para la institución, aconsejan a la administración y operan como agentes de cambio para traer nuevos conocimientos a la empresa. Los trabajadores de los datos son empleados como secretarias, contadores o vendedores, cuya función principal es procesar, usar o diseminar información para la institución. Los administradores realizan trabajo de conocimiento y de datos.
Agregar "Más información .." en Blogger
“Leer más” o “Seguir leyendo“, es uno de los trucos más solicitados por todos los usuarios Blogger, y por el décimo aniversario de esta plataforma, desde Blogger in Draft se estrena el Reed More de forma nativa, es decir, incorporado a tu blog sin tener que modificar nada en tu plantilla.
Uso
Hay dos formas de utilizar en Leer más y están en función del editor que se use. Entonces, para usar esta función, entra desde Blogger Draft, si estas en modo visual (Redactar) da clic en el icono de “Insertar salto linea” para cortar en ese punto tu artículo:
Construcción de los Sistemas de Información
PARTE III
Resumen Capítulo 11
CONSTRUCCIÓN DE LOS SISTEMAS DE INFORMACIÓN
Rediseño de la institución mediante sistemas de información
Entender por qué el proceso de desarrollar nuevos sistemas es un proceso de cambio organizacional.
El desarrollo de nuevos sistemas de información es una forma de cambio organizacional planeado que implica a muchas personas diferentes en la institución. Como los sistemas de información son entidades sociotécnicas, un cambio en los sistemas de información implica cambios en el trabajo, la administración y la institución.
Identificar los grupos que están involucrados en el desarrollo de sistemas.
La mayoría de las instituciones hoy en día tienen estructuras administrativas bien establecidas para el control del desarrollo de los sistemas. Todos los sistemas medianos y grandes implican administración de directivos, gerentes y supervisores, así como profesionales en sistemas de información. Las instituciones medianas y grandes en general tienen un comité corporativo guía de sistemas de información para asignar los recursos a los proyectos de sistemas. El equipo de proyectos es directamente responsable del desarrollo del sistema.
Identificar las actividades principales en el proceso de desarrollo de sistemas. Las actividades centrales en el desarrollo de los sistemas son el análisis de sistemas, diseño, programación, prueba, conversión y producción y mantenimiento de sistemas. El análisis de sistemas es el estudio y análisis de los problemas de los sistemas existentes y la identificación de requerimientos para su solución. El diseño de sistemas proporciona las especificaciones para una solución de sistemas de información, demostrando cómo sus componentes técnicos y organizacionales embonan.
BASES TÉCNICAS DE LOS SISTEMAS DE INFORMACIÓN
PARTE II
Resumen Capítulo 6
Las computadoras y el procesamiento de la información
Identificar los componentes de hardware de un sistema típico de cómputo.
El moderno sistema de cómputo tiene cinco componentes principales: un procesador central (que consiste en el CPU y el almacenamiento primario, los dispositivos de entrada, los dispositivos de salida, el almacenamiento secundario y los dispositivos de comunicación).
Describir cómo se representa y procesa la información en un sistema de cómputo.
Las computadoras digitales almacenan y procesan información bajo la forma de dígitos binarios llamados bits. Una cadena de 8 bits se llama byte. Existen diversos patrones de códigos para ordenar los dígitos binarios en caracteres. Los más conocidos son EBCDIC y ASCII.
Suscribirse a:
Entradas (Atom)